 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Visual Analytics Framework for Explaining and Diagnosing Transfer Learning Processes
Sep 15, 2020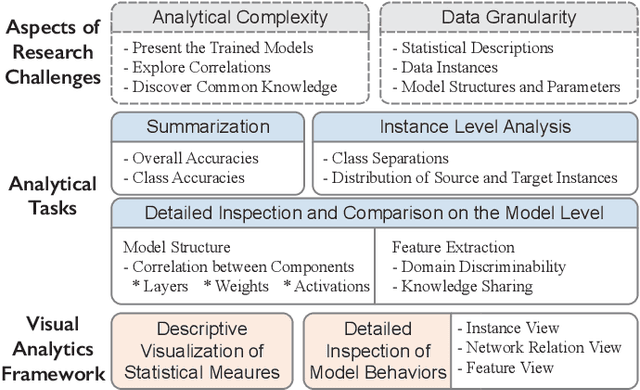
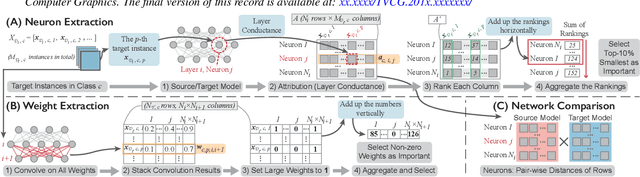
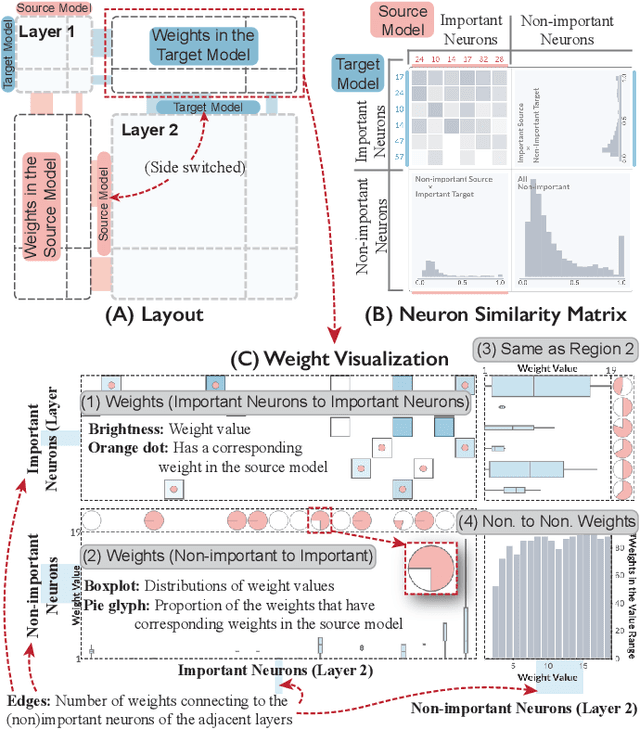

Many statistical learning models hold an assumption that the training data and the future unlabeled data are drawn from the same distribution. However, this assumption is difficult to fulfill in real-world scenarios and creates barriers in reusing existing labels from similar application domains. Transfer Learning is intended to relax this assumption by modeling relationships between domains, and is often applied in deep learning applications to reduce the demand for labeled data and training time. Despite recent advances in exploring deep learning models with visual analytics tools, little work has explored the issue of explaining and diagnosing the knowledge transfer process between deep learning models. In this paper, we present a visual analytics framework for the multi-level exploration of the transfer learning processes when training deep neural networks. Our framework establishes a multi-aspect design to explain how the learned knowledge from the existing model is transferred into the new learning task when training deep neural networks. Based on a comprehensive requirement and task analysis, we employ descriptive visualization with performance measures and detailed inspections of model behaviors from the statistical, instance, feature, and model structure levels. We demonstrate our framework through two case studies on image classification by fine-tuning AlexNets to illustrate how analysts can utilize our framework.
Unlearn What You Have Learned: Adaptive Crowd Teaching with Exponentially Decayed Memory Learners
May 25, 2018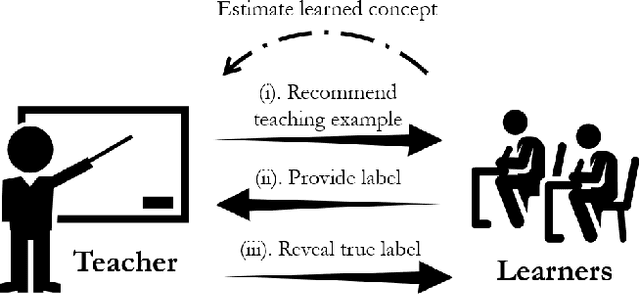
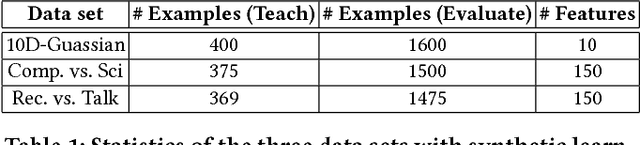
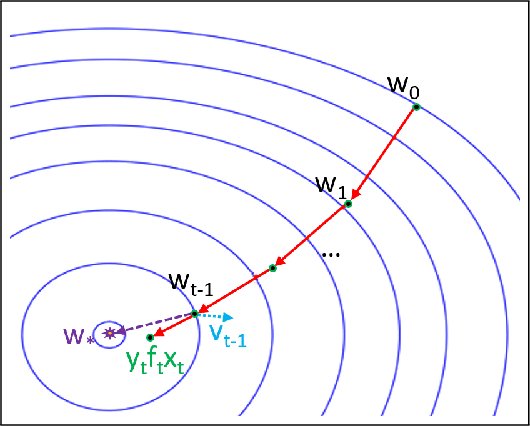
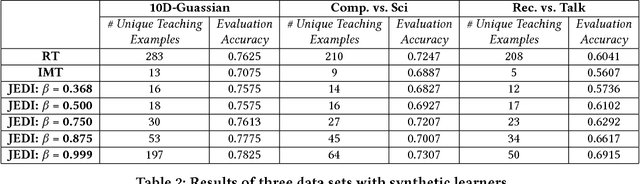
With the increasing demand for large amount of labeled data, crowdsourcing has been used in many large-scale data mining applications. However, most existing works in crowdsourcing mainly focus on label inference and incentive design. In this paper, we address a different problem of adaptive crowd teaching, which is a sub-area of machine teaching in the context of crowdsourcing. Compared with machines, human beings are extremely good at learning a specific target concept (e.g., classifying the images into given categories) and they can also easily transfer the learned concepts into similar learning tasks. Therefore, a more effective way of utilizing crowdsourcing is by supervising the crowd to label in the form of teaching. In order to perform the teaching and expertise estimation simultaneously, we propose an adaptive teaching framework named JEDI to construct the personalized optimal teaching set for the crowdsourcing workers. In JEDI teaching, the teacher assumes that each learner has an exponentially decayed memory. Furthermore, it ensures comprehensiveness in the learning process by carefully balancing teaching diversity and learner's accurate learning in terms of teaching usefulness. Finally, we validate the effectiveness and efficacy of JEDI teaching in comparison with the state-of-the-art techniques on multiple data sets with both synthetic learners and real crowdsourcing workers.